Pandarallel – Uma ferramenta simples e eficiente para paralelizar a computação do seu pandas em todas as suas CPUs
Este artigo é uma tradução de https://towardsdatascience.com/pandaral-lel-a-simple-and-efficient-tool-to-parallelize-your-pandas-operations-on-all-your-cpus-bb5ff2a409ae ; Escrito por https://medium.com/@manunalepa .
Complete Pandaral·lel repository and documentation is available on this GitHub page.
The library presented in this post is only supported on Linux & MacOS.
Que problema nos incomoda?
Com a biblioteca do pandas, quando você executa a seguinte linha:
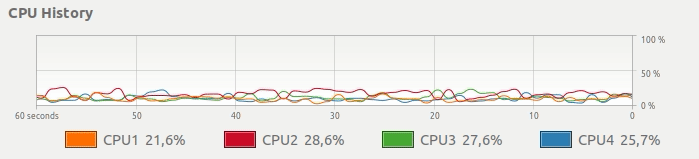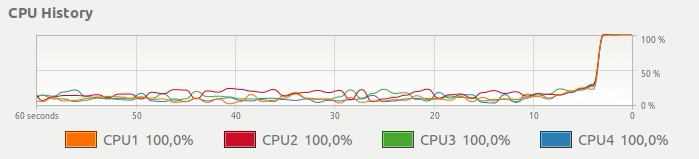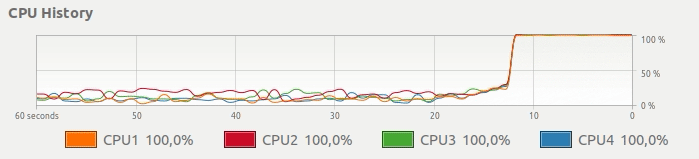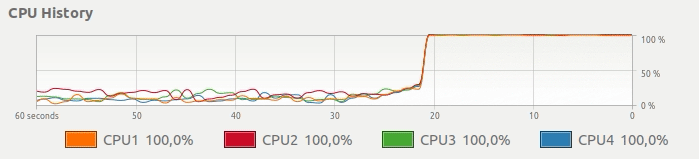
Você obtém este uso de CPU:
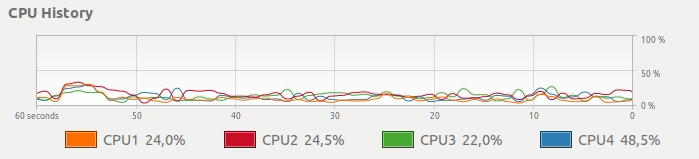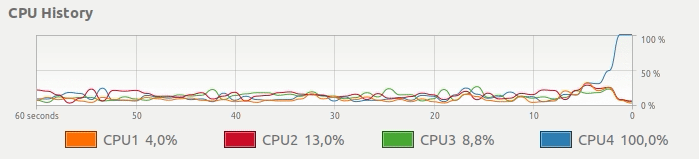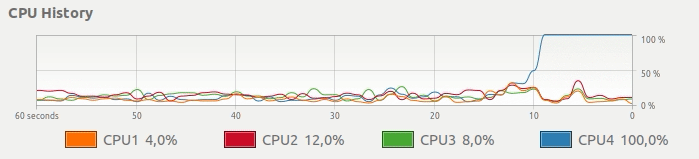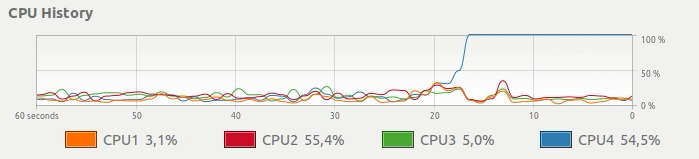
Mesmo que seu computador tenha várias CPUs, apenas uma é totalmente dedicada ao seu cálculo. Em vez desse uso de CPU, gostaríamos de uma maneira simples de obter algo assim:
Como Pandaral·lel ajuda a resolver esse problema?
A ideia do Pandaral·lel é distribuir o cálculo do seu pandas por todas as CPUs disponíveis no seu computador para obter um aumento significativo de velocidade.
Instalaçao
No Windows, Pandaral·lel funcionará apenas se a sessão Python (python, ipython, jupyter notebook, jupyter lab, …) for executada a partir do subsistema Windows para Linux (WSL). No Linux e no macOS, nada de especial precisa ser feito.
Import & Initialization:
USO
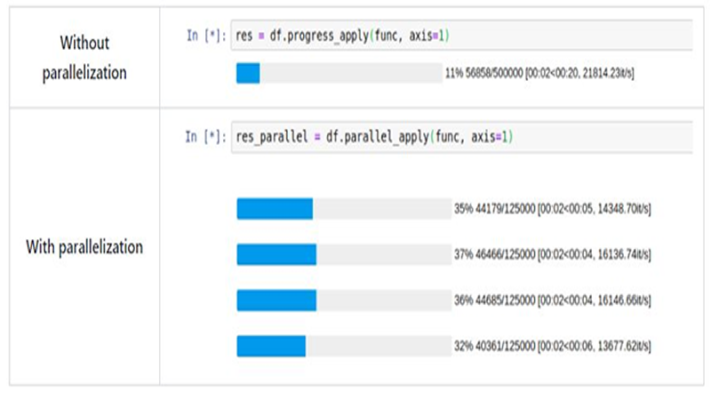
Com um caso de uso simples com um DataFrame df do pandas e uma função para aplicar func, basta substituir o clássico apply por parallel_apply
E pronto! Observe que você ainda pode usar o método de aplicação clássico se não quiser paralelizar a computação. Você também pode exibir uma barra de progresso por CPU em funcionamento passando progress_bar = True na função de inicialização.
E com um caso de uso mais complicado com um DataFrame df pandas, duas colunas deste DataFrame column1 e column2, e uma função para applyfunc:
Benchmark
Para quatro dos exemplos disponíveis aqui, na seguinte configuração:
SO: Linux Ubuntu 16.04
Hardware: Intel Core i7 @ 3,40 GHz – 4 núcleos
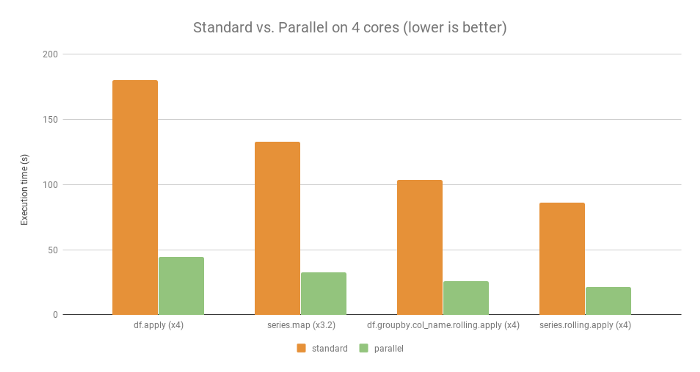
Exceto para df.groupby.col_name.rolling.apply, onde a velocidade aumenta apenas em um fator x3,2, a velocidade média aumenta em cerca de fator x4, que é o número de núcleos no computador usado.
Como isso funciona sob o capô?
Quando parallel_apply é chamado, Pandaral·lel:
- Instancia uma memória compartilhada do plasma Pyarrow, então
Cria um subprocesso para cada CPU e pede a cada CPU para trabalhar em uma subparte do DataFrame, entãoCombinar todos os resultados no processo pai.
A principal vantagem de usar uma memória compartilhada em comparação com outro meio de comunicação entre processos é que não há serialização / desserialização que pode ser muito expansiva para a CPU.
Se você achar esta ferramenta útil, mas se um recurso estiver faltando, escreva uma nova solicitação de recurso aqui