
Uma abordagem em contêiner usando: Apache Kafka, Spark, Cassandra, Hive, Postgresql, Jupyter e Docker-compose.
Os recursos de extração são um dos processos essenciais em pipelines de aprendizado de máquina. Infelizmente, quando o volume de dados cresce rapidamente, a execução de operações repetitivas em pipelines ETL torna-se cara. Uma solução simples para esse problema é construir um armazenamento de recursos, onde você pode armazenar recursos para reutilizar em diferentes projetos de aprendizado de máquina. O objetivo desta postagem é propor um guia sobre a construção de uma loja de recursos para fins de estudos ou implantação.
Você pode verificar mais sobre as lojas de recursos aqui. Além disso, você pode verificar o repositório Git para esta postagem aqui.
Usaremos a estrutura Butterfree para construir nosso pipeline de ETL. Acordo com seus autores: A ideia principal é que este repositório seja um conjunto de ferramentas para facilitar ETLs.
A ideia é usar Butterfree para fazer upload de dados para um armazenamento de recursos, para que os dados possam ser fornecidos para seus algoritmos de aprendizado de máquina.
O armazenamento de recursos é onde os recursos para modelos de aprendizado de máquina e pipelines são armazenados. Uma característica é uma propriedade individual ou característica de uma amostra de dados, como a altura de uma pessoa, a área de uma casa ou uma característica agregada como os preços médios das casas vistos por um usuário no último dia. Um conjunto de recursos pode ser considerado um conjunto de recursos. Finalmente, uma entidade é uma representação unitária de um contexto de negócios específico.
Simulando o seguinte cenário:
- Temos uma fonte de dados JSON de streaming com eventos de pedidos da Starbucks sendo capturados em tempo real.
- Temos um conjunto de dados CSV com mais informações sobre bebidas.
Objetivo:
Queremos analisar o JSON da fonte de streaming, realizando operações de agregação e armazenar todas as linhas em uma estrutura barata (como s3) e obter transações mais recentes em um banco de dados de baixa latência como Cassandra.
Desejamos ter uma saída com o esquema:
- id_employer: int
- name_employer: string
- name_client: string
- payment: string
- timestamp: timestamp
- product_name: string
- product_size: string
- product_price: int
- percent_carbo: float
- final_price: float
Solução usando a biblioteca Butterfree e a arquitetura acima:
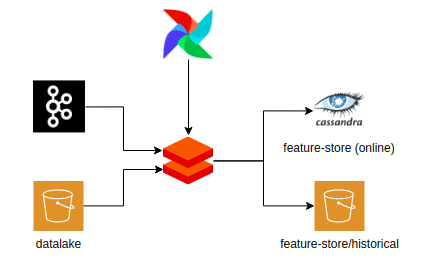
- Apache Kafka como fontes de dados (Streaming de dados de entrada);
- Um metastore hive para armazenar metadados (como seu esquema e localização) em um banco de dados relacional. (Para este tutorial, usaremos Postgresql)
- Apache Cassandra para armazenar dados mais recentes.
- Amazon S3 para armazenar recursos históricos ou visualizações de tabela para o modo de depuração. Nesta postagem, usaremos o modo de depuração para simplificar, mas você só precisa colocar suas credenciais da AWS para poder usar este recurso.
Toda a infraestrutura foi construída em docker-compose, com base neste repositório:
Optei por separar cada componente em um contêiner diferente, para que você possa substituir facilmente o que precisa em uma implantação real. Vamos explicar cada um deles:
- Cassandra: uma instância do Cassandra em execução para armazenar recursos online.
- Hive-metastore: contém uma instância de hive-metastore, um dos requisitos da estrutura Buterrfree. Um metastore é útil para armazenar tabelas e esquemas e pode usar diferentes bancos de dados. Aqui, PostgreSQL é a opção escolhida.
- Postgresql: contém uma instância de PostreesSQL configurada para hive-metastore.
- Spark: contém a centelha configurada com Jupiter Notebook e Python 3
- Namenode: o NameNode executa operações de namespace do sistema de arquivos, como abrir, fechar e renomear arquivos e diretórios. Ele também determina o mapeamento de blocos para DataNodes.
- Datanome: Os DataNodes são responsáveis por atender às solicitações de leitura e gravação dos clientes do sistema de arquivos. Os DataNodes também executam a criação, exclusão e replicação de blocos sob instrução do NameNode.
- Zookeeper: atua como um serviço centralizado e é usado para manter a nomenclatura e a configuração, acompanhando o status dos nós, tópicos e partições.
- Corretor: um corretor Kafka recebe mensagens de produtores e as armazena em disco com chave por deslocamento exclusivo. Além disso, permite que os consumidores busquem mensagens por tópico, partição e deslocamento.
Você precisa digitar docker-compose up -d para executar o aplicativo. Abra localhost / 8888 e execute o bloco de notas Kafka para iniciar o processo de streaming. Depois disso, você pode iniciar o bloco de notas ETL para criar seu armazenamento de recursos.
Você pode verificar o bloco de notas que produz o pipeline ETL aqui.